Metric-based evaluations#
Available on Pro and Enterprise plans
Metric-based evaluation is available on Pro and Enterprise plans. Registered community and Starter plan users can also use it for a single workflow.
What are metric-based evaluations?#
Once your workflow is ready for deployment, you often want to test it on more examples than when you were building it.
For example, when production executions start to turn up edge cases, you want to add them to your test dataset so that you can make sure they're covered.
For large datasets like the ones built from production data, it can be hard to get a sense of performance just by eyeballing the results. Instead, you must measure performance. Metric-based evaluations can assign one or more scores to each test run, which you can compare to previous runs. Individual scores get rolled up to measure performance on the whole dataset.
This feature allows you to run evaluations that calculate metrics, track how those metrics change between runs and drill down into the reasons for those changes.
Metrics can be deterministic functions (such as the distance between two strings) or you can calculate them using AI. Metrics often involve checking how far away the output is from a reference output (also called ground truth). To do so, the dataset must contain that reference output. Some evaluations don't need this reference output though (for example, checking text for sentiment or toxicity).
How it works#
Requires Google Sheets
Evaluations use Google Sheets to store the test dataset. To use evaluations, you must configure a Google Sheets credential.
- Set up light evaluation
- Add metrics to workflow
- Run evaluation and view results
1. Set up light evaluation#
Follow the setup instructions to create a dataset and wire it up to your workflow, writing outputs back to the dataset.
The following steps use the same support ticket classification workflow from the light evaluation docs:
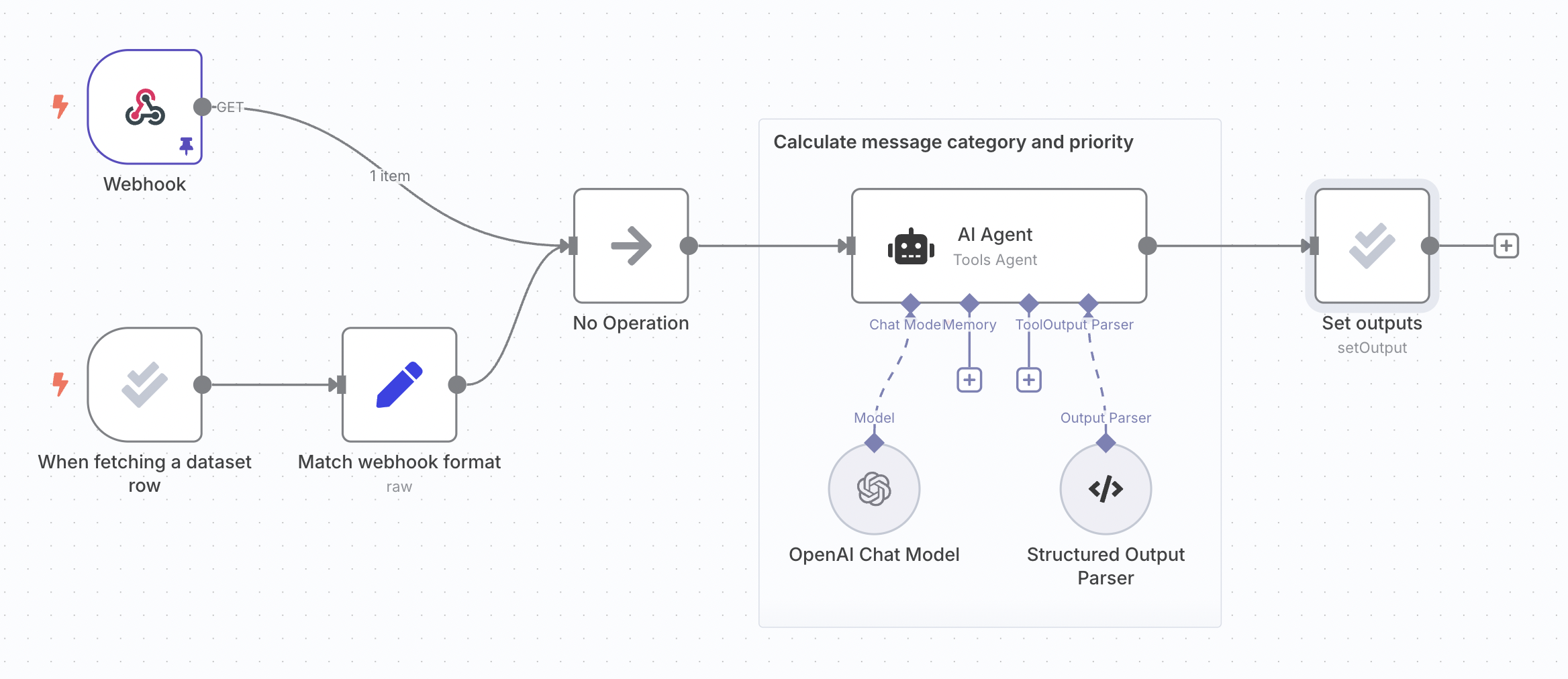
2. Add metrics to workflow#
Metrics are dimensions used to score the output of your workflow. They often compare the actual workflow output with a reference output. It's common to use AI to calculate metrics, although it's sometimes possible to just use code. In n8n, metrics are always numbers.
You need to add the logic to calculate the metrics for your workflow, at a point after it has produced the outputs. You can add any reference outputs your metric uses as a column in your dataset. This makes sure they it will be available in the workflow, since they will be output by the evaluation trigger.
Use the Set Metrics operation to calculate:
- Correctness (AI-based): Whether the answer's meaning is consistent with a supplied reference answer. Uses a scale of 1 to 5, with 5 being the best.
- Helpfulness (AI-based): Whether the response answers the given query. Uses a scale of 1 to 5, with 5 being the best.
- String Similarity: How close the answer is to the reference answer, measured character-by-character (edit distance). Returns a score between 0 and 1.
- Categorization: Whether the answer is an exact match with the reference answer. Returns 1 when matching and 0 otherwise.
- Tools Used: Whether the execution used tools or not. Returns a score between 0 and 1.
You can also add custom metrics. Just calculate the metrics within the workflow and then map them into an Evaluation node. Use the Set Metrics operation and choose Custom Metrics as the Metric. You can then set the names and values for the metrics you want to return.
For example:
- RAG document relevance: when working with a vector database, whether the documents retrieved are relevant to the question.
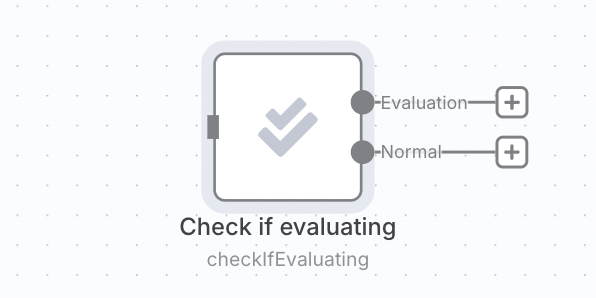
Calculating metrics can add latency and cost, so you may only want to do it when running an evaluation and avoid it when making a production execution. You can do this by putting the metric logic after a 'check if evaluating' operation.
3. Run evaluation and view results#
Switch to the Evaluations tab on your workflow and click the Run evaluation button. An evaluation will start. Once the evaluation has finished, it will display a summary score for each metric.
You can see the results for each test case by clicking on the test run row. Clicking on an individual test case will open the execution that produced it (in a new tab).